awk是一种用于处理数据和生成报告(manipulating data and generating reports)的脚本语言,无需编译,可使用变量、数学函数、字符串函数和逻辑操作符。
awk通常用于文本的模式扫描和处理(pattern scanning and processing),可对输入文件的每一行进行搜索(patterns be searched for in each line of a document),筛选出符合条件的字段,起到过滤文本的作用。
名字来源于三个开发者的姓的首字母:Alfred Aho, Peter Weinberger, and Brian Kernighan.
-f program-file
--file program-file
Read the AWK program source from the file program-file,
instead of from the first command line argument.
Multiple -f (or --file) options may be used.
-F fs
--field-separator fs
Use fs for the input field separator (the value of the FS predefined variable).
-v var=val
--assign var=val
Assign the value val to the variable var, before execution of the program begins.
Such variable values are available to the BEGIN block of an AWK program.FS The input field separator, a space by default. (输入内容字段之间的分隔符)
OFS The output field separator, a space by default.(输出内容的字段分隔符)
NF The number of fields in the current input record.(通常一列表示一个字段)
NR The total number of input records seen so far.(通常一行表示一个记录)AWK is a line-oriented language.
The pattern comes first, and then the action(action写在{}里面).
Either the pattern may be missing, or the action may be missing, but, of course, not both.
If the pattern is missing, the action is executed for every single record of input.
A missing action is equivalent to { print } which prints the entire record.
AWK patterns may be one of the following:
BEGIN
END
BEGINFILE
ENDFILE
/regular expression/
relational expression
pattern && pattern
pattern || pattern
pattern ? pattern : pattern
(pattern)
! pattern
pattern1, pattern2常用的Actions
Action statements consist of the usual assignment(赋值语句), conditional(条件语句), and looping(循环语句) statements found in most languages. The operators(运算符), control statements(控制语句), and input/output(输入输出) statements available are patterned after those in C(学过C语言就会发现全是熟悉的感觉).
运算符Operators:
(...) Grouping
$ Field reference.
++ -- Increment and decrement, both prefix and postfix.
^ Exponentiation (** may also be used, and **= for the assignment operator).
+ - ! Unary plus, unary minus, and logical negation.
* / % Multiplication, division, and modulus.
+ - Addition and subtraction.
space String concatenation.
| |& Piped I/O for getline, print, and printf.
< > <= >= != ==
The regular relational operators.
~ !~ Regular expression match, negated match. NOTE: Do not use a constant regular expression (/foo/) on the left-hand side of a ~ or !~. Only use one on the right-hand side. The expression /foo/ ~ exp has the same meaning as (($0 ~ /foo/) ~ exp). This is usually not what was intended.
in Array membership.
&& Logical AND.
|| Logical OR.
?: The C conditional expression. This has the form expr1 ? expr2 : expr3. If expr1 is true, the value of the expression is expr2, otherwise it is expr3. Only one of expr2 and expr3 is
evaluated.
= += -= *= /= %= ^=
Assignment. Both absolute assignment (var = value) and operator-assignment (the other forms) are supported.常见的输入输出语句:
print Print the current record(只写print则打印整行).
print expr-list Print expressions(可罗列print哪些字段).
print expr-list >file Print expressions on file(可直接写到文件去).
printf fmt, expr-list Format and print(指定打印的格式,同C语言,详情可通过man awk查看).
printf fmt, expr-list >file Format and print on file(可直接写到文件去).常见的数学函数:
atan2(y, x) Return the arctangent of y/x in radians.
cos(expr) Return the cosine of expr, which is in radians.
exp(expr) The exponential function.
int(expr) Truncate to integer.
log(expr) The natural logarithm function.
rand() Return a random number N, between 0 and 1, such that 0 ≤ N < 1.
sin(expr) Return the sine of expr, which is in radians.
sqrt(expr) The square root function.
srand([expr]) Use expr as the new seed for the random number generator. 常见的字符串函数:
gsub(r, s [, t]) 字符串替换
length([s]) 字符串长度
split(s, a [, r [, seps] ]) 字符串分割放于数组已知文件hg38_refGene.csv如下:
#bin,name2,name,chrom,strand,txStart,txEnd,exonCount
1278,HDDC3,NM_001286451,chr15,-,90930917,90932569,4
1918,CHRNA1,NM_000079,chr2,-,174747594,174764472,9
85,MPDZ,NM_001261407,chr9,-,13105703,13279564,45
178,AMD1,NM_001287216,chr6,+,110874783,110895712,5
1161,POLK,NM_016218,chr5,+,75511831,75599821,15
965,CRELD2,NM_001135101,chr22,+,49918629,49927540,11
1017,ZNF835,NM_001005850,chr19,-,56662651,56671755,2
1150,LIMK1,NM_001204426,chr7,+,74093155,74122525,15
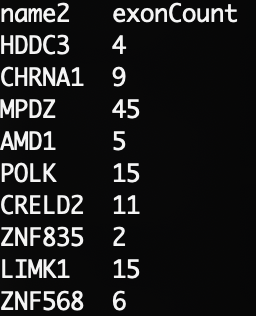
866,ZNF568,NM_001204836,chr19,+,36916328,36952743,6# 以逗号为分隔符,提取第2和第8个字段
# 写法:BEGIN{变量初始化}{action}
awk 'BEGIN {FS = ","; OFS = "\t"} {print $2, $8}' hg38_refGene.csv | head
# 也可以写成:选项 '{action}'形式
awk -F "," -v OFS="\t" '{print $2, $8} ' hg38_refGene.csv | head
# 上述输出形式为print expr-list这种写法
# 自定义变量
awk 'BEGIN {version = "hg38"; FS = ","; OFS = "\t"} {print version, $2, $8}' hg38_refGene.csv | head
# 也可以写成:
awk -v version="hg38" 'BEGIN{FS=",";OFS="\t"}{print version,$2,$8} ' hg38_refGene.csv | head
awk -v version="hg38" -v FS="," -v OFS="\t" '{print version,$2,$8} ' hg38_refGene.csv | head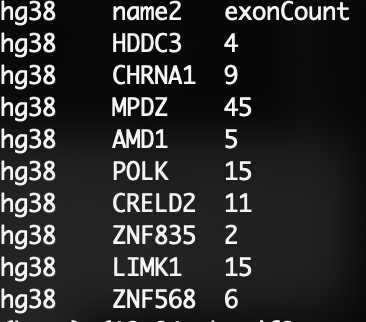
# 变量赋值和运算
awk 'BEGIN {FS = ","; OFS = "\t"; sum = 0; count = 0;} {count++; sum+=$8}END{print "average exoncount is: " sum/count}' hg38_refGene.csv
####### 输出结果如下:
####### average exoncount is: 9.17675# 文本过滤
# 可以在{action}中用if语句来设置过滤条件
awk 'BEGIN{FS=",";OFS="\t"} {if($4=="chrY" && $6>6000000 && $6<7000000) print $2,$8} ' hg38_refGene.csv | head
awk 'BEGIN{FS=",";OFS="\t"} {if($2=="TP53") print $2,$8} ' hg38_refGene.csv | head
awk 'BEGIN{FS=",";OFS="\t"} {if($2~"^MIR") print $2,$8} ' hg38_refGene.csv | head
# 也可以写成:'selection _criteria {action}'
# 数字支持科学计数法
awk -F "," -v OFS="\t" '$4=="chrY" && $6>6e6 && $6<7e6{print $2,$8} ' hg38_refGene.csv | head
awk -F "," -v OFS="\t" '$2~/TP53/{print $2,$8} ' hg38_refGene.csv | head
awk -F "," -v OFS="\t" '$2~/TP/ && $2!~/^TP/{print $2,$8} ' hg38_refGene.csv | head